Mit ipython-sql gibt es eine Möglichkeit SQL direkt in den Code-Blöcken Jupyter Notebooks zu verwenden und auch mit Python weiterzuverarbeiten.
Strukturierte Daten lassen sich in der Regel in Datenbanken erfassen und anschließend weiter verarbeiten. Dabei stellt das ipython-sql Paket eine Erweiterung zur Verfügung mit der direkt SQL Anfragen auf der Datenbank ausgeführt und das Ergebnis direkt weiterverwendet werden kann. Im Hintergrund verwendet das Paket dafür SQLAlchemy, was eine weit verbreitete Bibliothek zur Abstraktion von Datenbankanfragen ist. Über Plugins werden verschiedene Datenbanken wie SQLite, MariaDB, PostgreSQL und viele mehr unterstützt. Selbstverständlich lässt sich SQLAlchemy auch direkt verwenden, jedoch kann ipython-sql die Arbeit an einigen Stellen schon erleichtern.
Installation
Die Installation kann direkt wieder über das Tool pip erfolgen.
Wurde JupyterLab noch nicht installiert, kann im Artikel "JupyterLab zur Analyse und Forschung" nachgelesen werden, wie dies gemacht wird.
Das Paket ipython-sql wird wie folgt installiert.
$ pip install ipython-sql
Verwendung
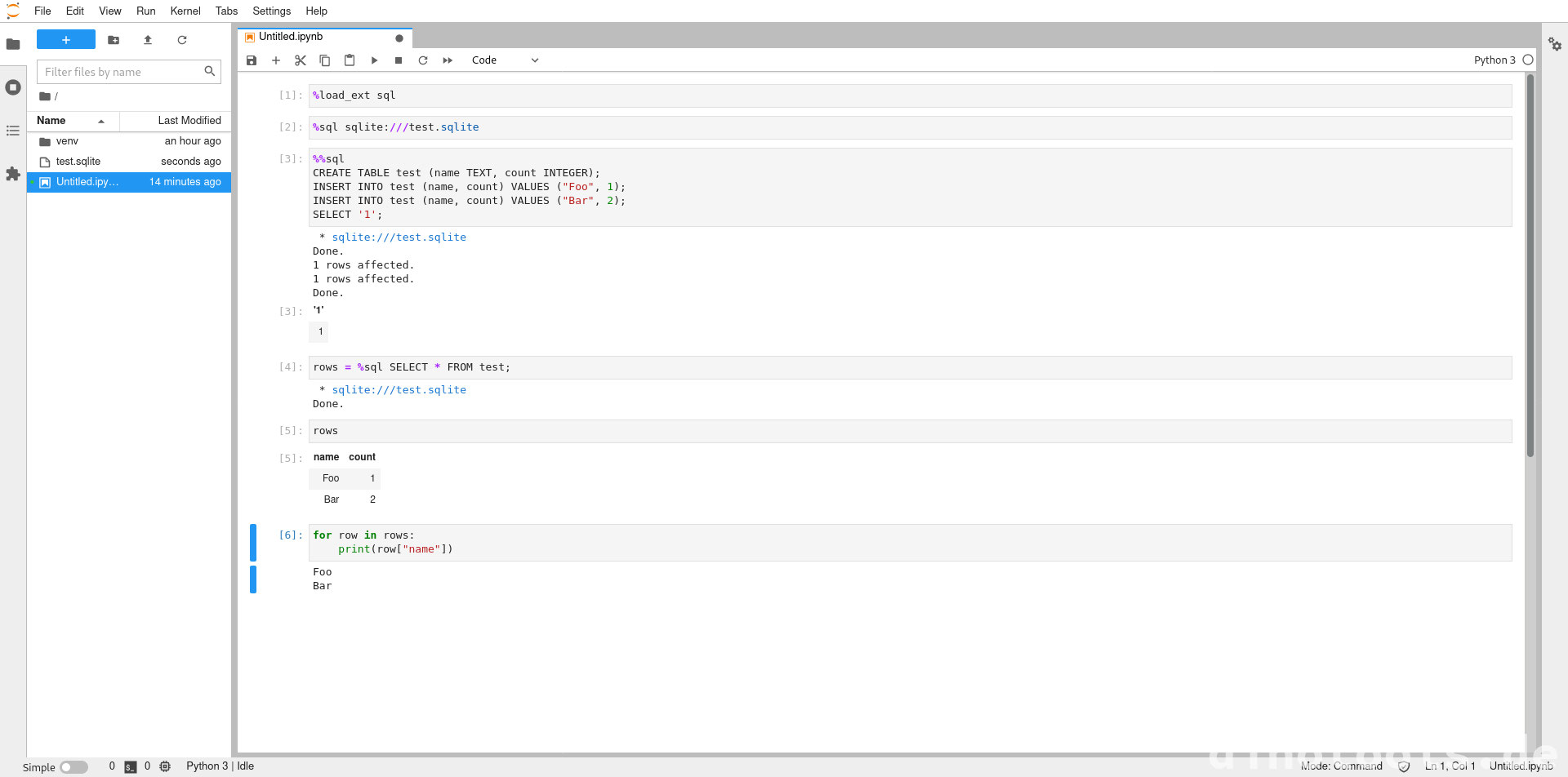
Zu erst muss die Erweiterung entsprechend im Notebook geladen werden. Dies wird mit dem folgenden Befehl realisiert.
War alles erfolgreich stehen Anschließend die Befehle %sql und %%sql zur Verfügung.
Der erste erlaubt es ein SQL Abfrage durchzuführen und beim zweiten sind mehrere möglich.
%load_ext sql
Für unseren Test verwenden wir eine SQLite Datenbank, die im selben Ordner wie das Notebook liegt.
%sql sqlite:///test.sqlite
Ist dies geschafft kann per SQL Befehl eine neue Tablle und zwei Testdatensätze eingefügt werden. Das SELECT als letzter Befehl vermeidet lediglich eine Fehlermeldung, die sonst erscheint, weil die INSERT Befehle keine Daten zurückliefern.
%%sql
CREATE TABLE test (name TEXT, count INTEGER);
INSERT INTO test (name, count) VALUES ("Foo", 1);
INSERT INTO test (name, count) VALUES ("Bar", 2);
SELECT '1';
Anschließend können die Daten wieder abgefragt und direkt in eine Variable gespeichert werden.
rows = %sql SELECT * FROM test;
Wird die Variable einfach ausgegeben, wird automatisch eine Tabelle mit den Daten ausgegeben.
rows
Wie bereits erwähnt können die Daten auch direkt weiterverarbeitet werden. Im Beispiel werden dann jeweils "Foo" und "Bar" ausgegeben. Bei größeren Datensätzen sollte aus Performancegründen darauf verzichtet werden alles auszugeben.
for row in rows:
print(row["name"])
Bilder
Fazit
Selbst verständlich können die Abfragen auch direkt über Python und mit den entsprechenden Bibliotheken realisiert werden, so ist es jedoch wesentlich einfacher. Schön war auch, dass die Ergebnisse gleich in Form von Tabellen ausgegeben werden. Hier muss zwar auf die größe des Datensatzes geschaut werden, jedoch hilft dies sich einen ersten Überblick zu verschaffen.
Links
- Webseite: Jupyter (englisch)
- Webseite: IPython (englisch)
- Webseite: ipython-sql (englisch)